Spring 프레임워크의 OkHttp 의존성 제거
OkHttp란?
OkHttp는 HTTP/2 지원, 내장 캐시, 쉬운 사용법 등으로 Android 계열에서 널리 사용되고 0에 가까운 의존성으로 Java 라이브러리 진영에서도 자주 사용되었던 오픈소스 HTTP 클라이언트입니다.
Square Inc.(현재는 BLOCK Inc.)의 오픈소스 팀에서 관리하는 오픈소스 프로젝트 중에 하나입니다.
이런 특징으로 인해 Spring 진영을 비롯해서 단위테스트 프레임워크 계의 핫 아이템인 Testcontainers에서도 사용하는 등 범용적이고 신뢰할 수 있는 클라이언트입니다.
Spring Framework에서 사용하는(했던) OkHttp
Spring Framework에서 REST API를 호출하기 위한 모듈인 RestTemplate이나 RestClient는 HTTP 통신을 위한 추상화 모듈만 제공할 뿐이고 실제 HTTP 통신은 HTTP Client 모듈에 의존합니다.
org.springframework.http.client 패키지를 보면 대략 어떤 HTTP Client 모듈이 있는지 알 수 있습니다.
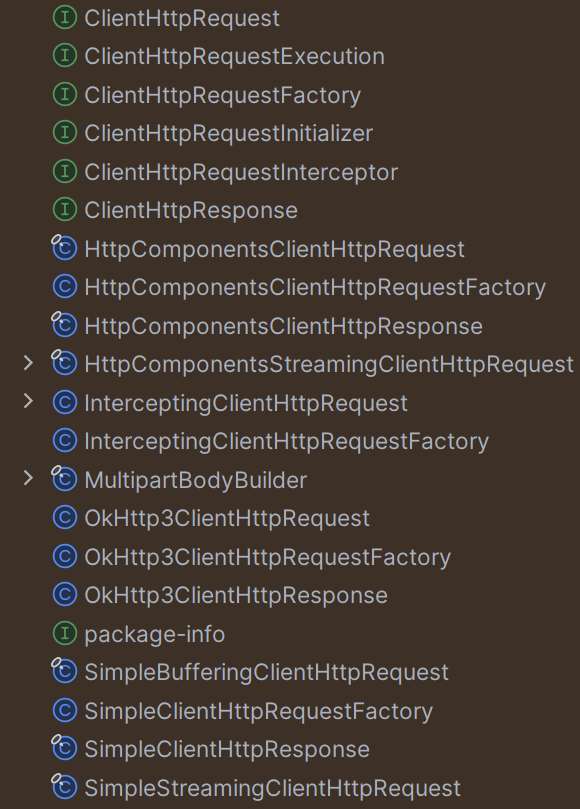
spring-web 6.0 버전의 org.springframework.http.client 패키지
위 이미지를 보면 알 수 있듯이 Spring은 6.0 버전 대까지는 아래 HTTP 클라이언트들을 기본 제공했습니다.
HttpComponentsClientHttpRequestFactory: Apache의HttpClientOkHttp3ClientHttpRequestFactory: OkHttp3의OkHttpClientSimpleClientHttpRequestFactory: JDK의HttpURLConnection
사건의 발단
문제는 이렇게 잘 사용되던 OkHttp에서 2019년 하나의 변화를 시도하면서 시작되었습니다.
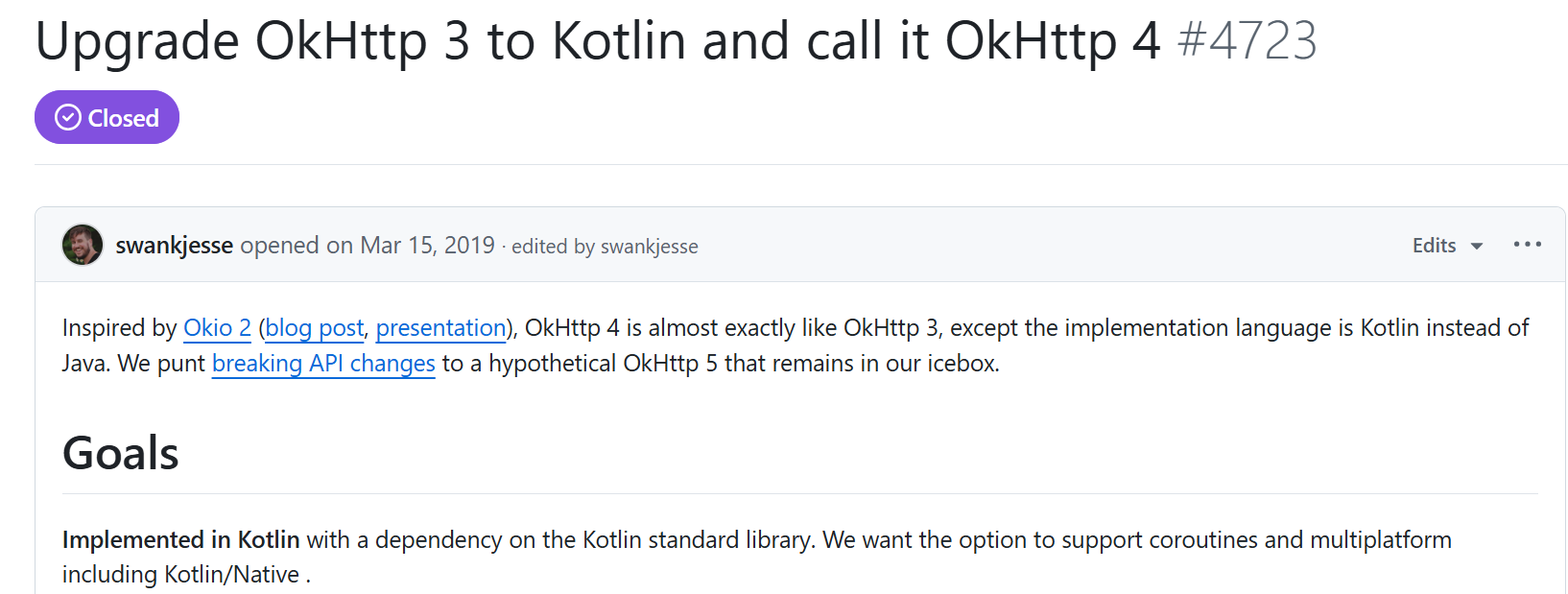
OkHttp의 Kotlin 전환 선언
바로 OkHttp 3의 코드를 모두 Kotlin으로 전환하고, Kotlin standard library를 추가하여 OkHttp 4로의 변화를 시도한 것입니다.
이 무렵 Square에서 Kotlin에 굉장히 매료되었는지 Java로 된 오픈소스 프로젝트들을 대거 Kotlin으로의 전환을 시도합니다.
Android 진영에 많은 기여를 하던 Square이어서 그런지 Kotlin으로의 전환은 빨랐습니다.
그러면서 자신들의 라이브러리가 두루 이용되고 있다는 것을 알고 있던 Square였기 때문에 이전 버전과 100% 호환성을 제공하겠다고 약속했습니다.
반응
하지만 해당 이슈에서 볼 수 있듯이 Zero-dependency에 가깝던 Java 라이브러리가 Kotlin 런타임의 큰 의존성이 생긴다는 점은 Java 오픈소스 진영에겐 반갑지 않았습니다.
Testcontainers for Java의 제작자이면서 Java Champion이기도 한 Sergei Egorov는 아쉬움을 표현했습니다.
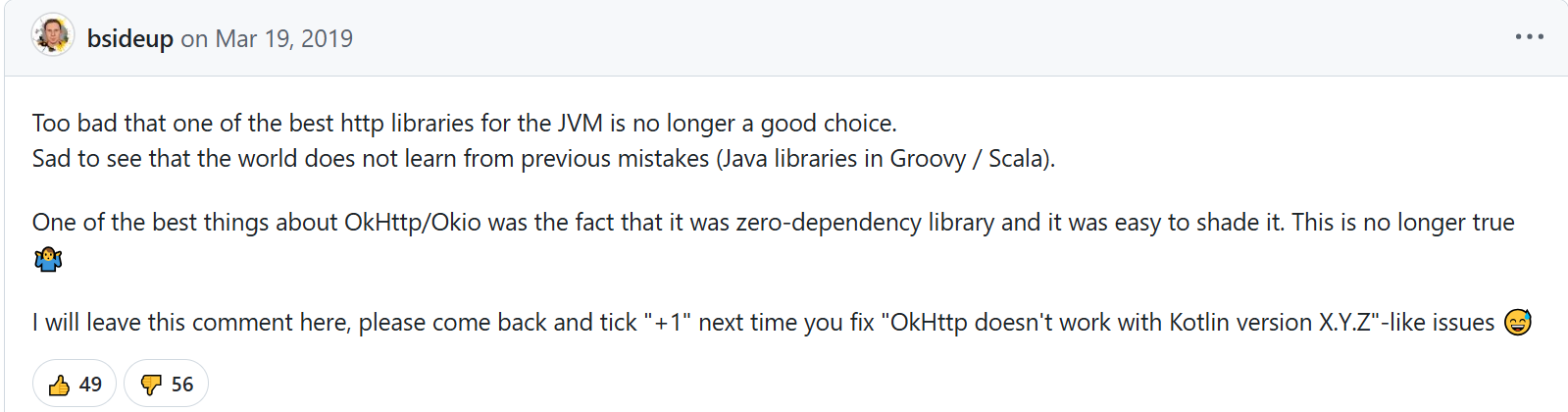
Sergei Egorov의 코멘트
최고의 JVM HTTP 라이브러리 중 하나였던 OkHttp가 이제 더이상 좋은 선택이 아니게 되어서 참 유감입니다.
세상이 이전의 실수(Scala, Groovy로 만든 Java 라이브러리)에서 교훈을 얻지 못한 것이 슬픕니다.OkHttp가 정말 좋았던 점은 다른 의존성이 없었고 shade하기 좋았던 점이었습니다. 이제 더이상 그렇지 않겠네요.
여기에 댓글을 남겨놓을테니, 다음에 ‘OkHttp가 Kotlin X.Y.Z 버전과 호환되지 않습니다’와 같은 이슈를 만나면 여기에 와서 👍를 눌러주세요.
또, 자신의 라이브러리를 OkHttp보다는 덜 유명하긴 한데 많이 쓰이는 Testcontainers라고 소개하면서 보일러플레이트를 제거하려고 다른 언어까지 쓰는 OkHttp를 더이상 사용할 수 없다며 약간의 조롱 섞인 코멘트도 덧붙였습니다.
Spring의 반응
선언한대로 OkHttp 4는 2019년에 릴리즈되었습니다. 하지만 Spring은 OkHttp3이 아주 잘 만들어진 라이브러리여서 그런지 바로 걷어내지 않았습니다.
Spring Boot에서도 2.6.X 버전까지는 OkHttp 3의 버전을 관리해주다가 2.7.0부터는 OkHttp 4로 버전을 업그레이드하는 등 계속해서 사용하는 듯한 모습이었습니다.
하지만 더이상 지원되지 않는 버전의 라이브러리는 계속해서 사용할 수 없었고, 특히 Web과 관련된 라이브러리는 더욱더 그렇습니다. TLS의 최신 싸이퍼에 대한 지원이 되지 않는 점 등이 치명적인 보안 취약점이 될 수 있기 때문입니다.
그리고 Spring Boot가 공식 지원하는 OkHttp 4 버전을 계속 쓰게 놔두자니 자신들의 프로젝트에 거대한 Kotlin 라이브러리 의존성이 생기는 것이 탐탁치 않았을 것이라고 추측합니다.
결국 Spring Web은 OkHttp3Client 시리즈를 6.1 버전에서 Deprecated 처리하고 6.2 버전에서 삭제하기로 합니다.
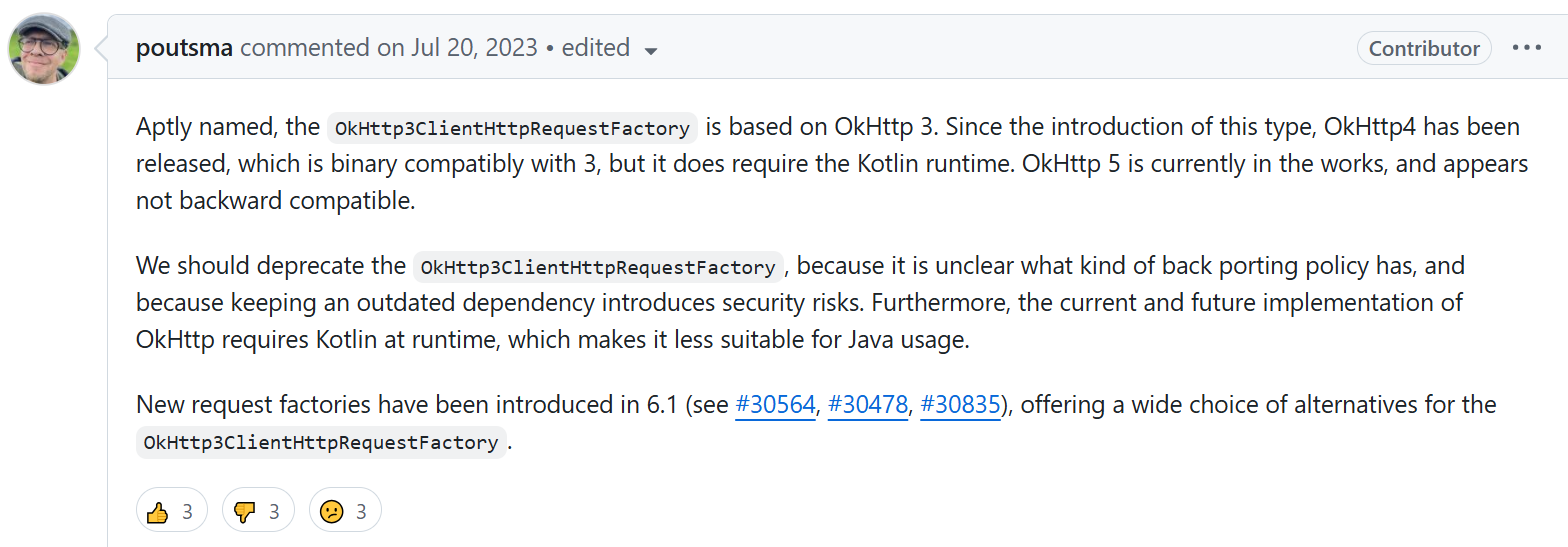
Spring 이슈
이름에 걸맞게 OkHttp3ClientHttpRequestFactory는 OkHttp 3을 기반으로 합니다. 이후 3과 호환이 가능한 OkHttp4가 출시되었지만, 여기에는 Kotlin 런타임이 필요합니다.
OkHttp 5는 현재 개발 중이며 이전 버전과 호환되지 않는 것으로 보입니다. 어떤 종류의 백 포팅 정책이 있는지 불분명하고 오래된 종속성을 유지하면 보안 위험이 발생하므로 OkHttp3ClientHttpRequestFactory를 더 이상 사용하지 않아야 합니다.
또한 현재 및 향후 OkHttp 구현에는 런타임에 Kotlin이 필요하므로 Java 사용에는 적합하지 않습니다. 6.1에 새로운ClientHttpRequestFactory가 도입되어OkHttp3ClientHttpRequestFactory를 대체할 수 있는 다양한 선택의 폭이 생겼습니다.
새로운 HTTP 클라이언트 도입
Java HTTP 클라이언트의 주류였던 OkHttp를 제거함과 동시에 다른 좋은 HTTP 클라이언트를 도입했습니다.
JdkClientHttpRequestFactory: JDK 11부터 추가된HttpClientJettyClientHttpRequestFactory: Jetty의HttpClientReactorClientHttpRequestFactory: Netty의HttpClient(6.2 버전)
Spring Boot의 대응
Spring Framework에서 OkHttp3을 Deprecated 처리함에 따라 가장 밀접한 Spring Boot 역시 기민하게 움직였습니다.
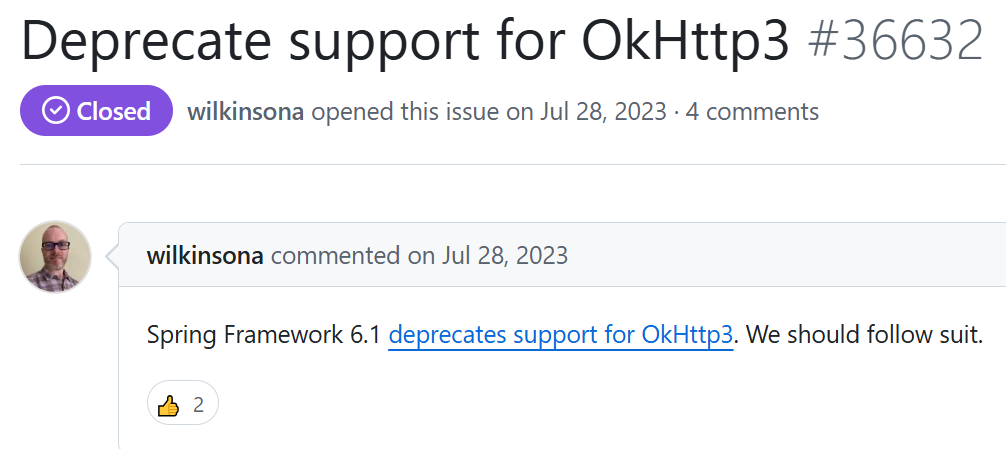
Spring Boot 이슈
Spring Boot v3.4 부터는 spring-boot-dependencies의 BOM에서 OkHttp의 의존성 버전을 제거했습니다. 따라서, Spring Boot 프로젝트에서 OkHttp 클라이언트를 사용하기 위해서는 이제 버전을 직접 명시해야 합니다.
소견
처음에는 Kotlin으로 만든 라이브러리가 무슨 문제가 있는지 의아했습니다. 하지만 Kotlin으로 컴파일된 jar 라이브러리를 Java 프로젝트에서 실행하려면 kotlin-stdlib 모듈이 필요하다는 것이 치명적인 단점이었습니다.
kotlin-stdlib이 Java 프로젝트에 포함되면 Kotlin을 실행할 수 있는 런타임이 들어오게 되어서 Java 파일 안에서 Kotlin에만 있는 함수나 coroutine 등을 실행할 수 있게 됩니다.
잘 사용하면 장점이 될 수도 있는 강력한 라이브러리이지만, Kotlin을 사용할 계획이 없는 프로젝트에 HTTP 호출만을 위해 1MB가 넘는 라이브러리가 포함되는 것은 분명히 단점도 있습니다. 많은 Java 오픈소스 프로젝트들은 이런 이유로 OkHttp를 걷어내는 작업들을 진행한 것으로 보입니다.
하지만 품질 좋은 HTTP API를 제공하는 Feign은 아직 OkHttp에 대한 지원을 중단하지 않았습니다.
요즘 Spring Cloud OpenFeign을 사용하는 프로젝트가 많아졌는데, Feign의 HTTP 클라이언트를 OkHttp로 선택한다면 자신의 Java 프로젝트에 불필요한 Kotlin 런타임이 포함된다는 사실을 인지해야 할 것입니다.
Spring의 Transaction 관리
스프링 부트로 프로젝트를 하면서 @Transactional이 주는 편리함을 당연하다고만 받아들였다.
그러다 보니 어떤 원리로 @Transactional 메소드가 트랜잭션으로서 작동하는지 모른 채로 사용해왔다.
나와 같은 고민을 한 사람들에게 스프링이 트랜잭션을 컨트롤하는 방법에 대해 공유하려고 한다.
개요
스프링이 트랜잭션을 관리하는 방법을 알아보기 위해 스프링이 없는 상태에서 트랜잭션을 관리하기부터 시작해서
스프링의 설계 사상을 한 단계씩 적용해가면서 차근차근 이해해보려고 한다.
즉, JDBC 레벨에서 트랜잭션을 관리하는 방법부터 시작하면서 스프링이 트랜잭션 관리를 설계하기 위해 어떤 생각들을
적용하는지 하나하나 알아보는 것이 기초를 다지기 좋다고 생각해서이다.
JDBC의 트랜잭션 관리
트랜잭션을 관리하는 방식이 JDBC이든, 스프링이든, Hibernate이든 관계없이 DB 트랜잭션은 아래와 같은 과정을 거친다.
1 | import javax.sql.DataSource; |
Java에서 데이터베이스의 트랜잭션을 시작하는 방법은 이 방법 밖에는 없다.
즉, 스프링도 최종적으론 이 JDBC API를 호출함으로써 트랜잭션을 관리하고 있다.
사실 스프링이 @Transactional 메소드에 대해서 해주는 역할은 위 동작을 해주는 것 뿐이다.
JDBC 트랜잭션 전파 옵션과 격리 수준
여기서 트랜잭션의 전파(propagation) 방식과 격리(isolation) 수준을 다르게 한다면 아래와 같다.
1 | import javax.sql.DataSource; |
스프링의 트랜잭션 관리
스프링에서는 위 작업을 단순화하기 위해서 PlatformTransactionManager 인터페이스를 만들었고 이 인터페이스는
JDBC가 트랜잭션을 시작하던 방법을 추상화했다.
프로그래밍적 트랜잭션 관리
PlatformTransactionManager를 통해 트랜잭션을 시작하고 관리하는 코드를 작성한다면 아래와 같이 작성할 수 있다.
1 | public Object doTransaction(PlatformTransactionManager platformTransactionManager) { |
스프링이 구체적으로 제시한 사용법은 TransactionTemplate에 잘 구현되어 있다.
TransactionTemplate.java
1 | public <T> T execute(TransactionCallback<T> action) throws TransactionException { |
이런 추상화 덕분에 스프링 사용자는 다음과 같이 간편해졌다.
- 더이상 JDBC의
Connection을open,commit,close등을 호출할 필요가 없어짐 - 예외 발생 시
RuntimeException으로 변경하기 때문에try-catch구문을 작성할 필요가 없어짐 - 트랜잭션 안에서의 동작만 기술하면 됨
하지만 이렇게 코드를 통한 트랜잭션 실행은 스프링이 근본적으로 추구하는 방향은 아니었다.
선언적 트랜잭션 관리
스프링에서 XML 방식으로 설정하는 것이 기본이었을 때에는 트랜잭션 또한 XML로 설정해야 했다.
XML을 통한 설정법은 이미 레거시(Legacy)가 되었으므로 자세히 알아보지는 않겠지만 이런 방식이 가능하다는 것을 알아두면 좋을 것 같다.
1 | <tx:advice id="transactionAdvice" transaction-manager="transactionManager"> |
스프링 AOP를 통해 Advice를 위와 같이 구성하고 아래와 같이 특정 빈에 적용할 수 있었다.
1 | <aop:config> |
그리고 UserService 클래스는 아래와 같을 것이다.
1 | public class UserService { |
AOP를 이용한 선언적 트랜잭션 관리를 사용함으로써 프로그래밍적 트랜잭션보다 코드는 훨씬 더 간단해졌다.
하지만 이를 위해 XML 파일을 작성하고 설정해야 했으며 XML 파일은 내용이 너무 장황했다.
@Transactional
이제 최근 스프링의 트랜잭션 관리 방법인 @Transactional 사용을 보자.
1 | public class UserService { |
이제 더이상 XML 설정도 필요 없고 try-catch, commit, rollback 같은 코드도 필요하지 않다.
하지만 다음 두 가지 설정을 해야한다.
- Spring Configuration 중에
@EnableTransactionManagement가 적용된 Configuration이 있어야 한다.
(Spring Boot에서는 자동으로 설정해준다.) PlatformTransactionManager빈이 등록되어 있어야 한다.
이 두 설정만 마치면 스프링은 자동으로 @Transactional이 있는 public 메소드에 대해 트랜잭션을 관리할 것이다.
즉, 스프링은 위의 코드를 아래와 같이 번역해 줄 것이다.
1 | public class UserService { |
어떻게 이게 가능한지 이제 파헤쳐보자.
CGLIB, JDK 프록시
내가 작성한 UserService의 save() 메소드는 SQL을 실행하고 id를 리턴할 뿐인데 스프링이 내가 짠 코드를 변경할 방법은 없다.
그 과정에서 스프링은 꼼수를 부린다. 내가 만든 UserService만 객체로 만드는 것이 아니라 프록시 객체도 같이 생성한다.
그리고 스프링의 IoC 컨테이너는 UserService빈을 필요로 하는 다른 곳에 의존성으로 주입해줄 때 프록시를 대신 주입한다.
CGLIB 라이브러리는 UserService를 상속한 프록시 객체를 만들어준다. (JDK 프록시는 방식이 약간 다르긴 여기서 다루진 않겠다.)
1 | public class UserController { |
즉, UserController에서 UserService의 save() 메소드를 호출하면, 진짜 UserService가 호출되는 것이 아니라
가짜로 만든 프록시의 save()가 호출되는 것이다.
PlatformTransactionManager 역할
그렇다면 이 과정에서 PlatformTransactionManager는 왜 필요한 걸까?
생성된 프록시는 직접 트랜잭션을 컨트롤하지 않는다. 대신 PlatformTransactionManager에게 이런 임무를 맡겨버린다.
예를 들어 DataSourceTransactionManager의 doBegin() 메소드의 소스코드를 보면 우리가 초반부에 알아본 방법과
동일하다는 것을 알 수 있다.
DataSourceTransactionManager.java
1 | public class DataSourceTransactionManager implements PlatformTransactionManager { |
스프링이 구현한 DataSourceTransactionManager는 우리가 처음에 알아본 JDBC로 트랜잭션을 시작하는 방법과 완전히 똑같다.
요약
트랜잭션을 편리하게 할 수 있게 스프링이 우리에게 해준 것은 반복된 코드를 추상화해준 것이다.
- 스프링은
@Transactional이 붙은 메소드(또느 클래스)를 찾아서 프록시 클래스를 만든다. - 프록시는
TransactionManager를 자체적으로 가지고 있고 트랜잭션 관리를 여기에 맡겨버린다. TransactionManager는 JDBC로 트랜잭션을 관리하는 방법과 동일하게 트랜잭션을 관리한다.
[Spring Security] 메소드 인가 (Method Security)
Spring Security 6.2.3 버전을 기준으로 작성했습니다.
Method Security란?
스프링 시큐리티를 처음 접할 때 기본적으로 다루는 인가는 요청 URI에 대한 인가인 것 같다.
1 |
|
위 코드처럼 빈을 만들고 requestMatchers()를 사용해서 API 엔드포인트에 인가를 적용하는 방식을 처음 접하게 된다.
규모가 작은 사이드 프로젝트에서는 해당 방식으로 인가를 처리해도 충분히 커버 가능하다.
그리고 도메인 권한이 중요하지 않으면 크게 문제가 없다.
하지만 도메인에 대한 권한을 엄격하게 관리하는 서비스이거나 대규모 프로젝트에서는
API 엔드포인트의 수도 늘어나기 때문에 엔드포인트만 검사하는 것만으로는 촘촘하게 권한을 검사하기 힘들 수 있다.
그래서 다음과 같은 경우에 Method Security를 사용하면 좋다:
- 권한 체크 로직이 복잡해서 세분화되어야 할 경우
- 서비스 레이어에서도 권한을 체크해야 할 경우
- 애너테이션 방식의 코드 스타일과 AOP를 지향할 경우
| API 레벨 | 메소드 레벨 | |
|---|---|---|
| 권한 수준 | 촘촘하지 않음 | 촘촘함 |
| 설정 방법 | Config 빈 | 메소드에 선언 |
| 설정 스타일 | DSL | 애너테이션 |
| 인가 표현식 | Ant, 정규식 등 | SpEL |
메소드 인가는 Spring AOP 기반으로 작동한다.
즉, 메소드 호출의 before와 after에 권한을 체크하고 싶은 경우 사용하면 된다.
메소드 시큐리티 활성화
메소드 레벨 인가를 활성화하기 위해서는 @Configuration이 설정된 빈에 @EnableMethodSecurity 를 추가해주어야 한다.
1 |
|
메소드 인가의 흐름
1 |
|
위와 같은 서비스가 있다고 가정하자.
그러면 readCustomer()라는 메소드에 대한 인가는 다음과 같은 흐름으로 적용된다.
- Spring AOP는
readCustomer()의 프록시 메소드를 만들어서 감싼다. readCustomer()의 프록시 메소드에서는AuthorizationManagerBeforeMethodInterceptor를 호출한다.- 인터셉터는
PreAuthroizeAuthorizationManager#check()를 호출한다. - AuthorizationManager는
@PreAuthorize안의 SpEL 표현식과Authentication을 담은 컨텍스트를 인터셉터에 제공한다. - 인터셉터는 컨텍스트에 담긴
Authentication과 표현식을 보고 권한 부여가 가능한지 체크한다. - 권한 체크에 통과하면 AOP는
readCustomer()를 호출한다. - 체크에 통과하지 못한다면
AccessDeniedException를 던진다. readCustomer()의 호출이 끝나고 리턴되면 프록시가AuthorizationManagerAfterMethodInterceptor를 호출한다.- 인터셉터는
PostAuthroizeAuthorizationManager#check()를 호출한다. @PostAuthorize안의 표현식이 통과하면 정상적인 흐름으로 종료된다.- 마찬가지로 통과하지 못하면
AccessDeniedException을 던진다.
애너테이션
메소드 인가를 설정하는 방법은 여러가지가 있지만 애너테이션 방식이 제일 권장된다.
애너테이션에서 권한을 검증하는 로직을 작성할 때는 여러가지 방법이 있는데
이 내용은 별도의 문서로 정리하겠다.
@PreAuthorize
@PreAuthorize는 메소드 호출 전, 권한을 검증하고 싶을 때 사용한다.
1 |
|
위 메소드는 호출하기 전에 Authentication 객체가 ROLE_ADMIN Role이 있는지 체크하고
Role이 없다면 AccessDeniedException이 던져진다.
MockUser를 사용해서 테스트를 작성할 수 있다.
1 |
|
@PostAuthorize
@PostAuthorize는 메소드가 호출되고 리턴될 때 권한을 검증하고 싶을 때 사용한다.
1 |
|
위 메소드는 리턴되는 Account 객체의 owner 프로퍼티가
Authentication 객체의 name 프로퍼티와 같을 때만 정상적으로 리턴되고
같지 않다면 마찬가지로 AccessDeniedException이 발생한다.
아래와 같이 테스트해볼 수 있다.
1 |
|
@PreFilter
@PreFilter는 메소드 호출 전 파라미터로 전달되는 객체들을 인가를 통해 필터링하고 싶을 때 사용한다.
1 |
|
위 메소드에서 파라미터로 전달되는 accounts 안에는
owner 프로퍼티가 Authentication의 name 프로퍼티와 같은 객체만 필터링돼서 전달된다.
1 |
|
위 테스트 코드에서 updateAccounts()의 파라미터로 2개의 Account 객체를 전달했지만,
@PreFilter로 인해 실제 메소드 내부에 전달되는 파라미터는 ownedBy 객체만 전달된다.
@PreFilter로 필터링할 수 있는 파라미터 타입은 배열, Collection, Map, Stream이다.
(Stream은 닫히지 않은 상태여야 한다.)
1 |
|
@PostFilter
@PostFilter는 메소드가 리턴하는 객체들을 인가를 통해 필터링하고 싶을 때 사용한다.
1 |
|
위 코드는 리턴되는 accounts 컬렉션에서 객체들의 owner 프로퍼티가
Authentication의 name 프로퍼티와 같은 객체만 필터링되어 리턴된다는 의미이다.
아래와 같은 테스트코드로 확인해볼 수 있다.
1 |
|
@PostFilter로 필터링할 수 있는 리턴 타입은 배열, Collection, Map, Stream이다.
1 |
|
주의사항
@PreFilter나@PostFilter를 사용해서 사이즈가 큰 컬렉션을 필터링하는 작업은
메모리를 매우 많이 소모한다. 자칫 잘못하면 OOM이 발생할 수도 있다.
그렇기 때문에 사이즈가 큰 컬렉션을 가져와서 필터링하기보다는
데이터를 가져올 때 먼저 필터링해서 가져오는 방식을 택해야 한다.
즉, SQL이나 NoSQL로 데이터를 가져올 때부터 적절한 조건식으로 데이터를 먼저 필터링해야 한다.
기타 애너테이션
@Secured
@Secured는 @PreAuthorize의 레거시 버전이며 사용하려면
@EnableMethodSecurity(securedEnabled = true) 로 변경해야 한다.
JSR-250 애너테이션
JSR-250 애너테이션에는 @RolseAllowed, @PermitAll, @DenyAll 등이 있으며 사용하려면
@EnableMethodSecurity(jsr250Enabled = true) 로 변경해야 한다.
클래스 레벨 애너테이션
1 |
|
위와 같이 클래스 레벨로 애너테이션을 추가할 수 있고 해당 클래스의 모든 메소드에 적용된다.
1 |
|
위처럼 예외로 다른 표현식을 사용해야할 경우에는 해당 메소드에 애너테이션을 오버라이드할 수 있다.
메타 애너테이션 (커스텀 애너테이션)
위에서 소개한 @PreAuthorize, @PostAuthorize 등의 애너테이션에 똑같은 표현식을
계속 적는 것은 분명 가독성과 유지보수 관점에서 좋지 않다.
이를 위해 메타 애너테이션이라 불리는 커스텀 애너테이션을 만들어서 대신 사용할 수 있다.
1 |
|
위처럼 애너테이션 인터페이스를 만들고
1 |
|
와 같이 커스텀 애너테이션으로 @PreAuthorize("hasRole('ADMIN')")와 같은 효과를 낼 수 있다.
Spring AOP 포인트컷(Pointcut)
포인트컷(Pointcut)이란?
포인트컷은 Advice가 언제 실행될지 조인 포인트 중에서 골라내는 작업이라고 할 수 있다.
즉, 어드바이스가 어떤 메소드들에서 실행될지 골라내는 작업이다.
스프링 AOP에서는 스프링 빈의 메소드 실행에 대한 조인 포인트만 제공하기 때문에 스프링에서 포인트컷은 스프링 빈의 메소드와 연결된다고 볼 수 있다.
포인트컷 선언
포인트컷을 선언할 때는 다음 두 가지가 필요하다.
- 시그니쳐 (Signature)
- 포인트컷 표현식 (Pointcut Expression)
AspectJ에서 시그니쳐란 쉽게 말해 Java의 메소드이다. 이름과 파라미터로 식별 가능한 고유한 메소드이고 꼭 void 타입이어야 한다.
포인트컷 표현식이란 어떤 메소드가 실행될 때 이 애스펙트가 적용되어야 하는지 나타내는 표현식이다.
AspectJ에서 포인트컷은 다음과 같이 선언할 수 있다.
1 | // 포인트컷 표현식 |
위 포인트컷의 시그니쳐는 anyOldTransfer라는 이름과 0개의 파라미터로 구성돼있다.
그리고 포인트컷 표현식은 @Pointcut("execution(* transfer(..))")가 된다.
스프링 AOP의 포인트컷 표현식
스프링 AOP에서 지원하는 AspectJ의 포인트컷 지정자 (Pointcut designator, PCD) 는 다음과 같다:
execution
어떤 메소드가 실행될 때인지를 지정한다.
execution([접근자] 타입 [클래스].이름(파라미터))
- 접근자:
public,private등의 접근 제어자. 생략 가능. - 타입: 메소드의 리턴 타입.
- 클래스: 패키지명을 포함한 클래스명. 생략 가능.
- 이름: 메소드 이름.
- 파라미터: 메소드의 파라미터 타입.
*: 모든 타입...: 0개 이상의 모든 파라미터.
1 |
예를 들어 위와 같은 포인트컷 표현식이 있다면
접근자는 public, 리턴 타입은 String, 클래스는 com.baeldung.pointcutadvice.dao.FooDao, 메소드 이름은 findById, 파라미터는 Long 타입 1개만 갖고 있는 메소드를 지정하는 것이다.
1 |
위 표현식에서는 접근자는 생략되었고 리턴 타입은 * 로 모든 타입이고, 클래스는 com.baeldung.pointcutadvice.dao.FooDao, 메소드 이름은 *로 모든 메소드이며 파라미터는 ..로 갯수와 타입에 상관없이 모든 메소드를 지정하게 된다.
within
어떤 타입 안에 있는 메소드인지 지정한다.
1 |
는 FooDao 내의 모든 메소드를 의미하고
1 |
는 com.baeldung 패키지와 그 하위의 모든 패키지의 모든 타입 안의 모든 메소드를 의미한다.
this 와 target
this와 target은 AOP가 프록시를 생성할 때 CGLIB 방식인지 JDK dynamic 방식인지에 따라 선택해야 한다.
만약 IFooService라는 인터페이스가 있고 이를 구현한 FooServiceImpl 클래스가 있다고 가정해보자.
1 | public class FooServiceImpl implements IFooService { |
이 경우에는 스프링 AOP는 JDK dynamic 프록시를 사용하기 때문에 target 표현식을 사용해야 한다.
1 |
A instanceof IFooService 가 true인 모든 A의 메소드를 의미한다.
만약 FooServiceImpl가 다음처럼 아무 인터페이스도 구현하지 않고 있다면,
1 | public class FooServiceImpl { |
이 경우에는 생성되는 프록시가 FooServiceImpl의 자식 클래스로 생성되기 때문에
1 |
처럼 사용해야 한다.
args
메소드의 파라미터로 전달된 런타임 객체의 타입이 지정된 타입일 경우에 적용된다.
예를 들어 어떤 메소드의 파라미터로 String 타입이 전달될 때 적용하고 싶다면
1 |
execution과 차이점
execution(* *(java.lang.String))은 String 타입을 파라미터로 받는다고 선언된 메소드를 의미하고
args(java.lang.String)은 런타임에 전달된 파라미터의 타입이 String 타입인 메소드를 의미한다.
다음과 같이 두 메소드가 있는데 하나는 List 타입으로 선언돼있고 하나는 ArrayList 타입으로 선언돼있다고 가정하자.
1 | public void method(List<String> list) {} |
그리고 만약 method(new ArrayList<>());를 호출한다고 하면
이 경우에 execution(* *(java.util.ArrayList))는 method2에만 적용되는 것이고
args(java.util.ArrayList)는 method와 method2 둘 다에 적용되는 것이다.
@target
위에서 설명한 target과 다르다는 것을 주의해야 한다.
지정한 애너테이션을 갖고 있는 클래스의 모든 메소드를 의미한다.
1 |
@args
위에서 설명한 args와 다르다는 것을 주의해야 한다.
메소드의 파라미터로 전달된 런타임 객체의 실제 타입이 지정된 애너테이션을 갖고 있는 클래스일 경우에 적용된다.
예를 들어 어떤 메소드의 파라미터로 @Entity가 붙은 클래스의 객체가 전달될 때 적용하고 싶다고 가정하면
1 |
|
로 지정하게 되면 @Entity가 붙은 객체가 전달되는 모든 메소드를 의미한다.
이렇게 지정한 포인트컷의 파라미터에 접근하려면 advice에서 JoinPoint 를 파라미터로 받아서 접근 가능하다.
1 |
|
@within
within과 다르다는 점을 주의한다.
within과 거의 비슷하지만 @within은 지정한 애너테이션을 갖고 있는 타입의 모든 메소드를 의미한다.
1 |
는 아래와 동일한 표현식이다.
1 |
@annotation
지정된 애너테이션을 갖고 있는 메소드에 적용된다.
@within은 지정된 애너테이션을 갖고 있는 타입의 모든 메소드에 적용되는 것이고 @annotation은 지정된 애너테이션을 갖고 있는 메소드에 적용되는 차이점이 있다.
예를 들어 @Loggable이라는 애너테이션을 만들어서 메소드에 추가한다면
@Loggable이 붙은 모든 메소드에 대해 아래와 같이 적용할 수 있다.
1 |
|
bean
이 지정자는 AspectJ에는 없는 지정자로 스프링 AOP에서 자체 지원한다.
지정한 빈의 모든 메소드를 의미한다. *를 통한 와일드카드 표현식을 지원한다.
이외의 PCD
스프링 AOP에서는 위에서 소개한 포인트컷 지정자 이외에 다른 AspectJ 지정자를 사용하면 IllegalArgumentException이 발생한다.
포인트컷 조합
포인트컷은 적용될 대상 메소드를 집합처럼 나타내는 표현식이므로 여러 포인트컷을 조합해서 집합처럼 사용할 수 있다.
사용 가능한 연산자는 다음과 같다.
&&: 두 포인트컷의 교집합||: 두 포인트컷의 합집합!: 여집합
포인트컷 공유
규모가 큰 애플리케이션을 개발할 때는 자주 사용되는 공통 포인트컷을 묶어서 하나의 클래스로 만들 것을 추천한다.
예를 들면, 아래와 같이 CommonPointcuts라는 클래스를 만들고
1 | package com.xyz; |
Advice를 만들 때 공통 포인트컷을 사용할 수 있다.
1 |
|
포인트컷 잘 작성하기
어떤 메소드가 해당 포인트컷에 적합한지 찾아내는 것은 비용이 많이 드는 작업이다.
특히 동적으로 생성된 빈의 메소드는 더욱더 비용이 많이 든다.
그래서 AspectJ는 컴파일할 때 포인트컷을 모두 찾아내서 검사하기 쉬운 메소드 순서로 정렬한다.
좋은 포인트컷을 작성하기 위해서는 이 포인트컷의 목표를 생각하고 최대한 메소드 집합의 범위를 좁혀야 한다.
포인트컷 지정자(PCD)는 다음 세 그룹으로 분류할 수 있다.
- Kinded
- 특정 조인포인트(메소드)만 선택 :
execution
- 특정 조인포인트(메소드)만 선택 :
- Scoping
- 조인포인트의 그룹을 선택 :
within
- 조인포인트의 그룹을 선택 :
- Contextual
- 문맥에 따라 다르게 선택 :
this,target,@annotation
- 문맥에 따라 다르게 선택 :
포인트컷을 잘 작성하기 위해서는 최소한 kinded와 scoping을 포함해야 한다.
Kinded 지정자만 선언하거나 Contextual 지정자만 선언한 포인트컷은 작동은 하지만 시간, 메모리 효율성에서 성능에 영향을 줄 수 있다.
Scoping 지정자는 특정 그룹만 대상으로 하면 되기 때문에 조인포인트를 찾아내는 게 매우 빠르다.
즉, 잘 작성된 포인트컷은 Scoping 지정자를 포함한 포인트컷이다.
가상 스레드 (Virtual Thread)
가상 스레드 도입 배경
이전부터 Project Loom에 대해서 관심이 많았다.
지금까지 자바 서버는 요청 트래픽이 몰리는 상황에서 값비싼 컨텍스트 스위치 비용을 지불해왔다.
이를 해결하기 위해 다양한 시도를 해왔다.
- Reactive Streams와 같은 비동기 API
- 코루틴을 자바에 추가하기
Spring WebFlux는 Reactive API를 훌륭하게 구현해서 스레드가 부족한 환경에서 성능을 개선했다.
또, JVM 진영의 코틀린에서 coroutine을 통해 메소드를 비동기적으로 호출할 수 있게 지원해줬다.
하지만 위의 시도들은 다음과 같은 이유로 자바의 표준이 되지 못했다
- 웹플럭스는 요청을 처리하는 순서가 보장되지 않아 디버깅을 단계별로 진행할 수 없고, 처리되는 스레드가 다를 수 있어 stack trace도 제공할 수 없었다.
- 자바 플랫폼에 코루틴 API를 적용하려면 엄청난 대규모 작업이 될 수 밖에 없다. 기존의 스레드 API를 사용해 개발했던 내용은 모두 걷어내야 한다.
코루틴을 사용하려면 코틀린을 사용하면 되지만, 여전히 자바를 사용하고 싶은 사람은 코루틴도 해결책이 아니었다.
이 때문에 Project Loom은 자바 방식으로 해결하기 위해 3가지 기능을 도입하기로 하는데 그 중 첫 번째가 가상 스레드(Virtual Thread)이다.
가상 스레드란?
가상 스레드는 한마디로 JVM에 의해 관리되는 경량 스레드이다.
기존의 JVM 스레드는 플랫폼 스레드(Platform Thread)라고 부르며 이는 OS 스레드를 래핑(Wrapping)한 스레드여서 OS 스레드와 일대일 관계였다.
플랫폼 스레드와 차이
플랫폼 스레드는 다음과 같은 단점이 있다.
- OS 스레드의 래퍼로 구현하기 때문에 사용가능한 스레드 수가 제한됨
- OS에 의해 생성되고 스케줄링되기 때문에 비용이 비싸고 컨텍스트 스위칭 비용도 비싸다
이에 비해 가상 스레드는 JDK에서 구현하고 제공하는 user-mode 스레드이다.
가상 스레드는 특정 OS 스레드에 연결되어 있지 않고 M:N 스케줄링을 사용한다. 가상 스레드의 수(M)가 더 적은 수(N)의 OS 스레드에서 실행되게 예약한다.
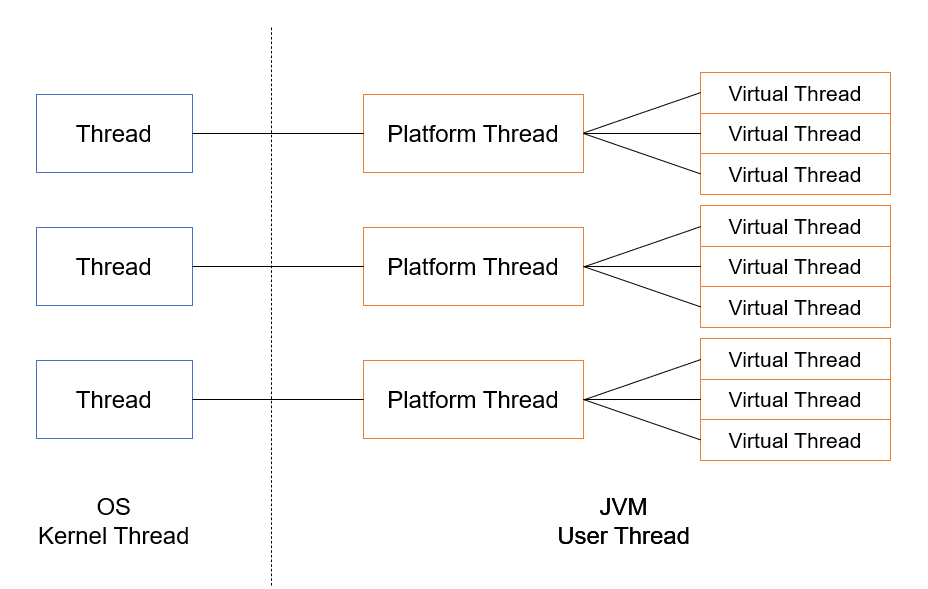
가상 스레드는 CPU에서 계산을 수행할 때만 OS 스레드를 사용한다.
가상 스레드에서 blocking I/O 작업을 시작할 때 자바는 non-blocking OS를 호출하고 가상 스레드를 임시로 중단한다.
기존 스레드 모델과 성능 비교
간단한 애플리케이션을 만들어서 성능 비교를 해보았다.
스프링 부트 버전
- Spring Boot 3.2.1
성능 테스트 도구
- Apache JMeter
테스트 환경 (VM)
- Centos7 x86_64
- CPU 1 core 1 Thread
- 1GB Memory
- JDK 21
요청을 받으면 300ms동안 sleep하고 리턴하는 간단한 API를 만들었다.
그리고 현재 스레드가 가상 스레드인지 확인하기 위해 Thread.currentThread().isVirtual을 사용하여 로그도 남겼다.
1 | package com.example.study.controller |
그리고 톰캣이 요청을 처리할 때 가상 스레드를 사용할 수 있게 Bean을 등록해주었다.
1 | package com.example.study.config |
이 Bean 설정은 Spring Boot 3.2 버전 이상에서는 application.properties에서spring.threads.virtual.enabled=true를 설정하면 자동으로 생성된다.
테스트 결과
처음에 가상유저를 100으로 했을 때는 플랫폼 스레드와 가상 스레드의 차이가 없었다.
이는 기본 스레드 풀 200개가 활성화되어서 별 차이가 없는 것 같았다.
500 가상 유저
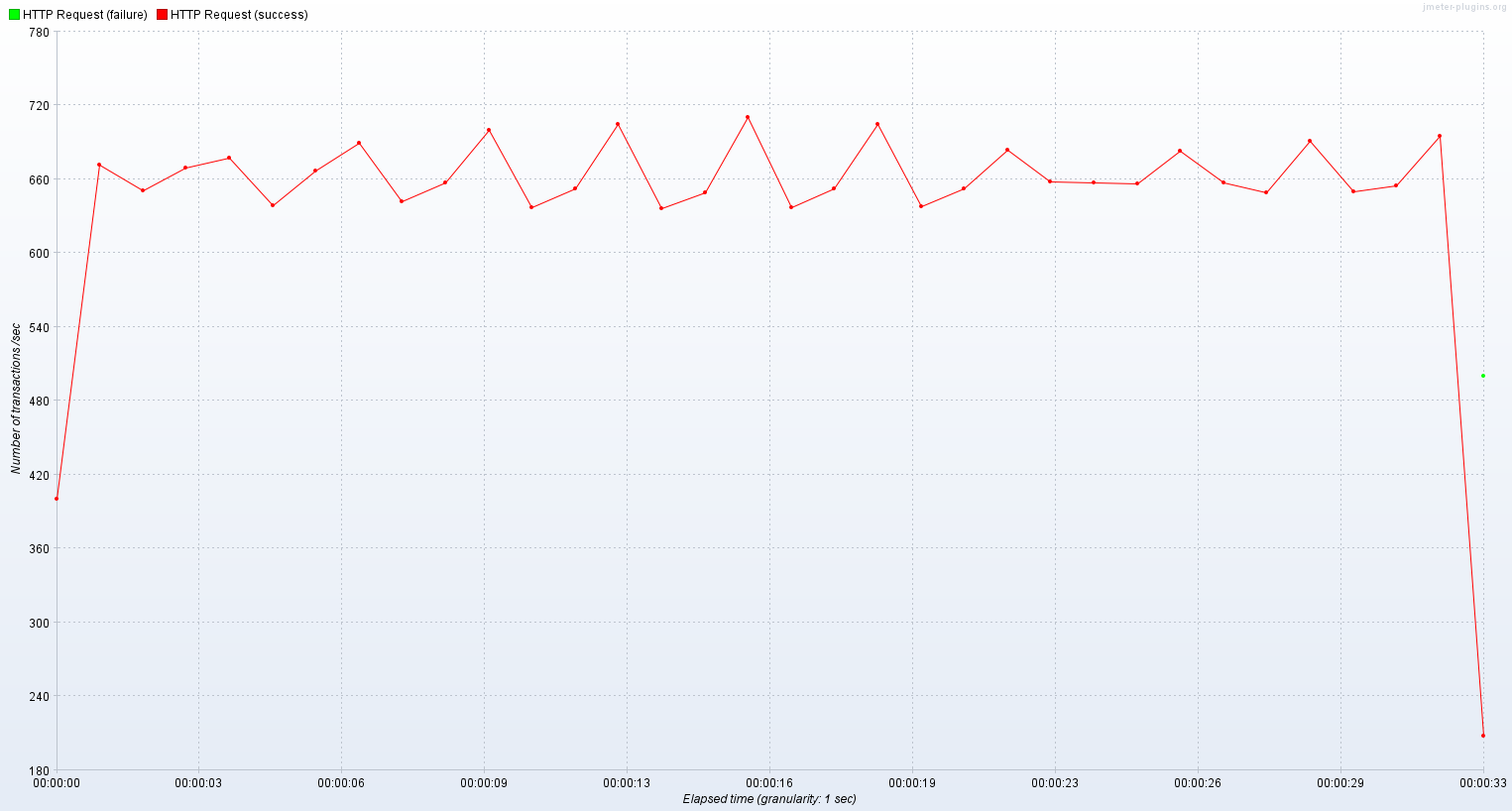
가상 스레드는 최대 스레드 풀을 상회하는 요청이 들어왔을 때 진가를 발휘했다.
기존 스레드
TPS
응답시간
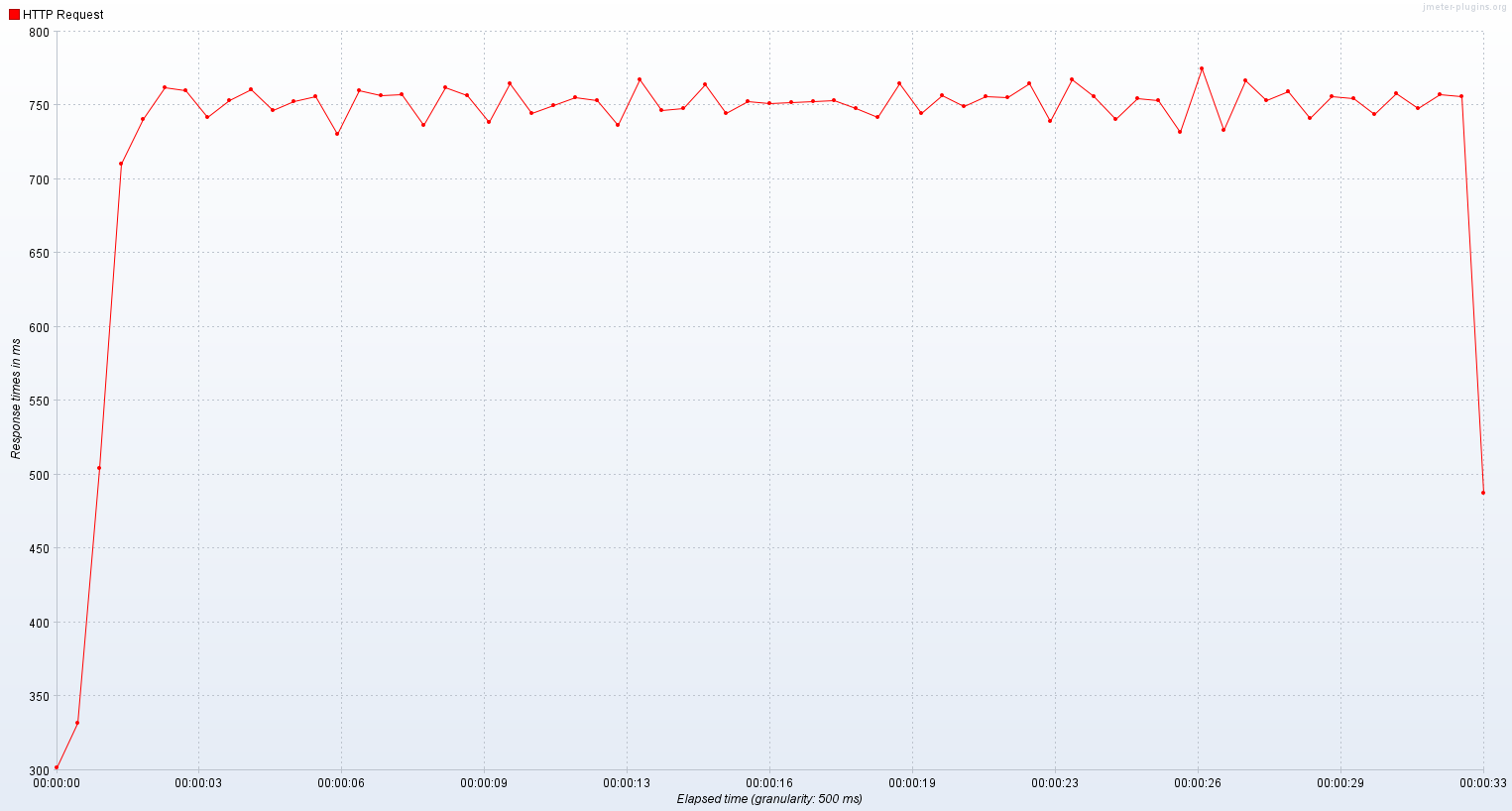
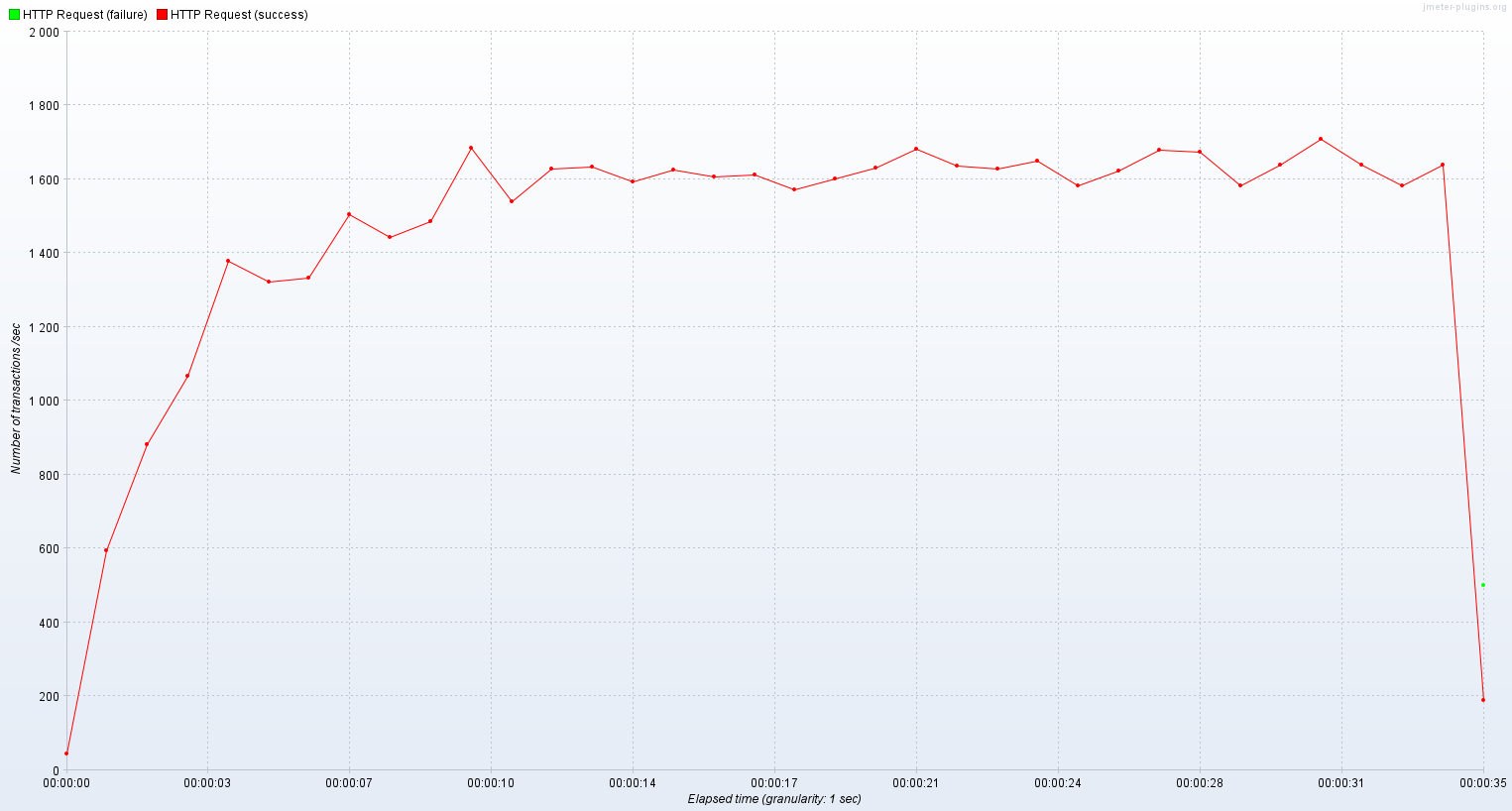
기존 스레드 모델에서는 650 ~ 700 TPS를 맴돌았고 평균 응답시간은 750ms였다.
가상 스레드
TPS
응답시간
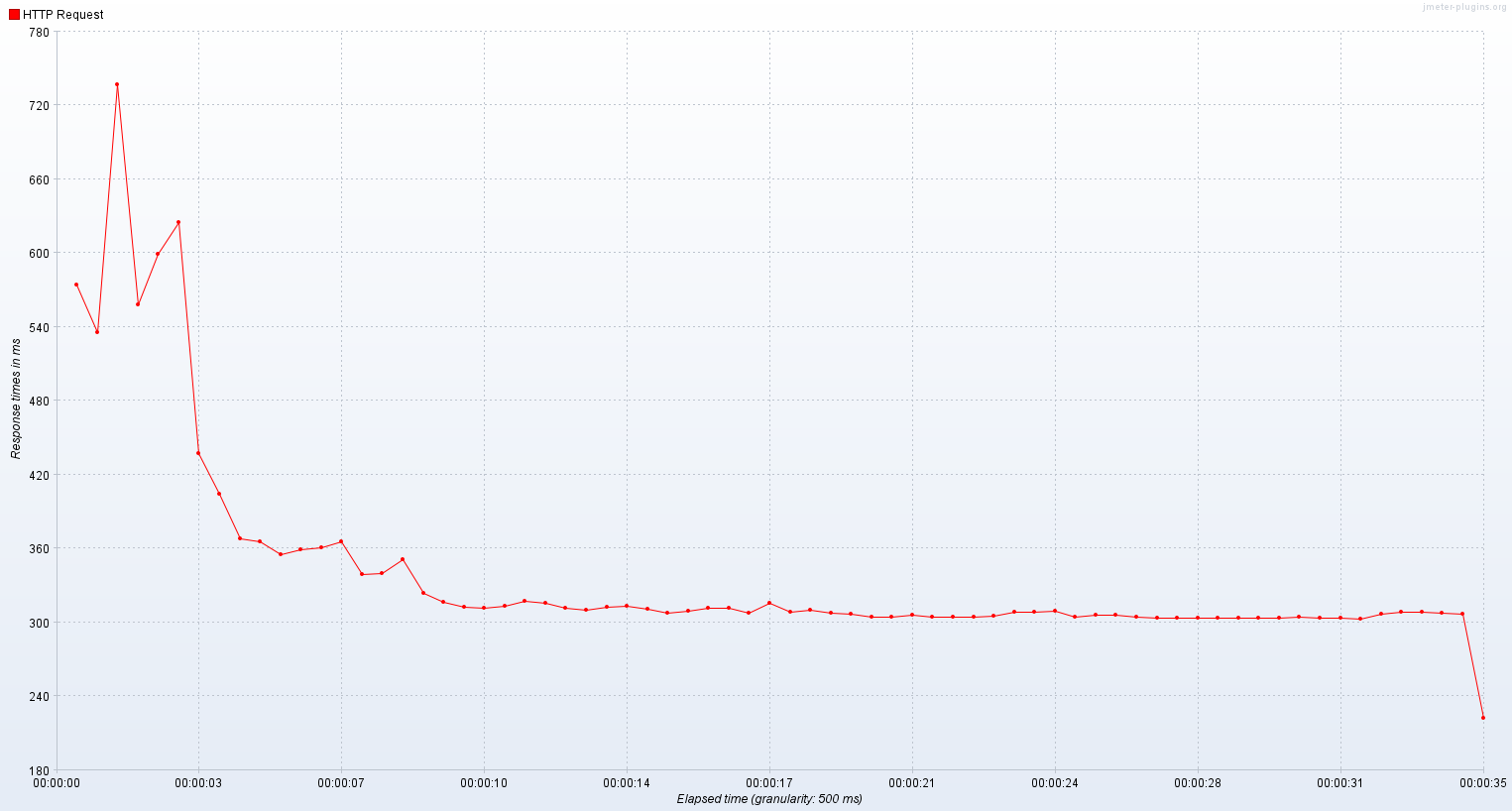
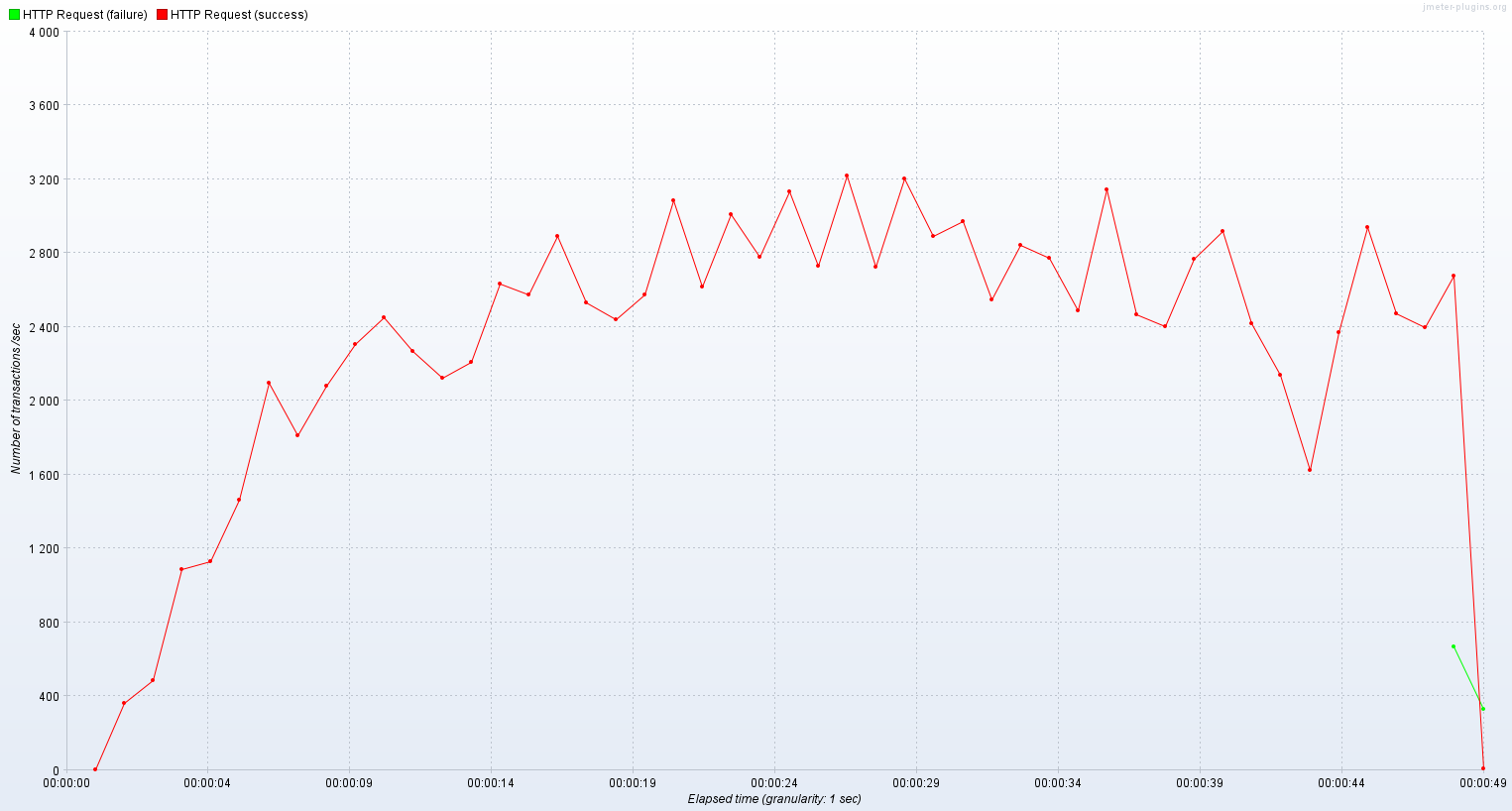
가상 스레드로 실행한 서버는 1400 ~ 1700 TPS를 기록했고 평균 응답시간은 초반을 제외하면 300 ~ 400ms 정도였다.
1000 가상 유저
이번엔 훨씬 더 많은 유저를 가정하고 테스트해보았다.
기존 스레드
TPS
응답시간
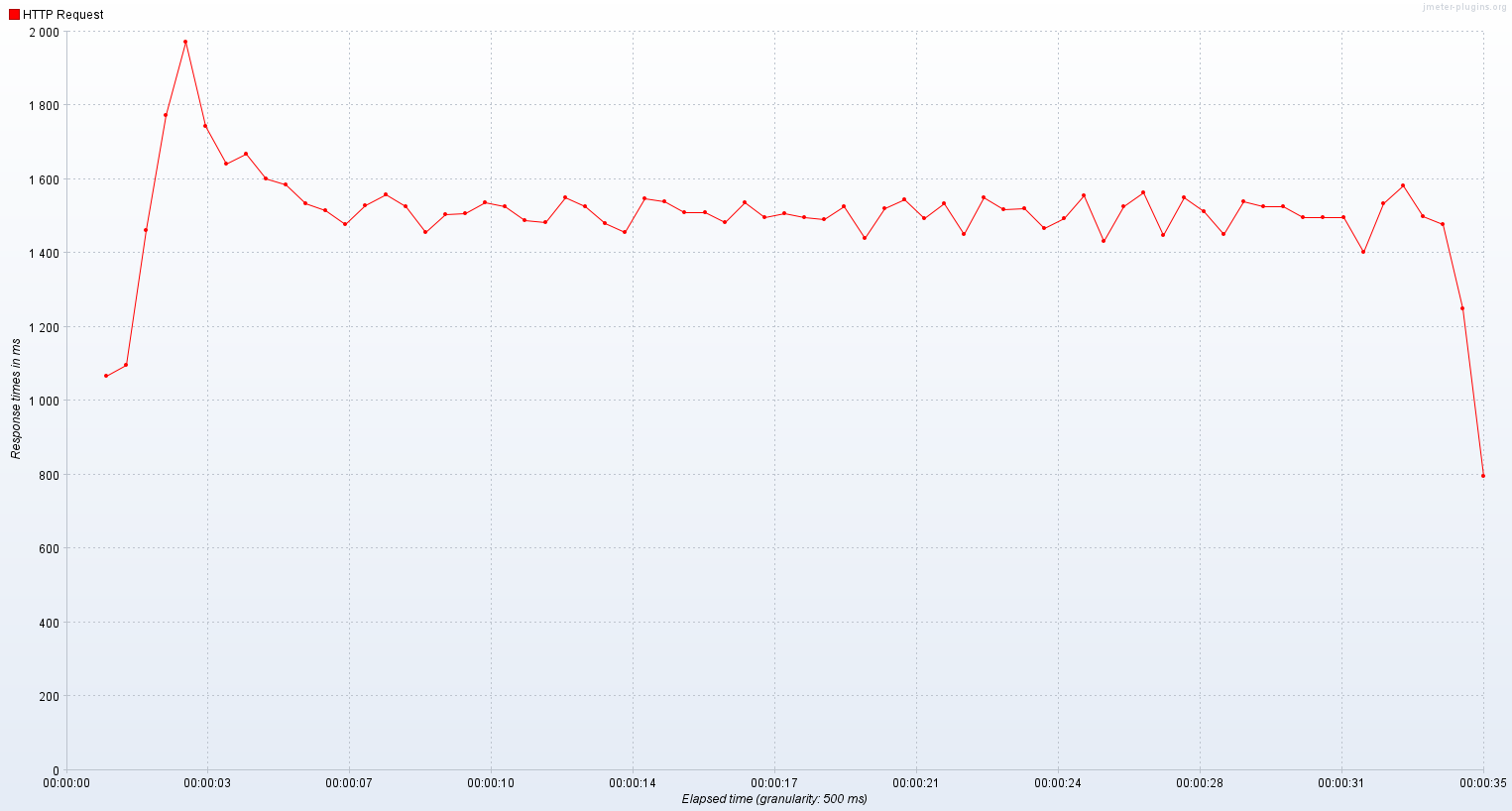
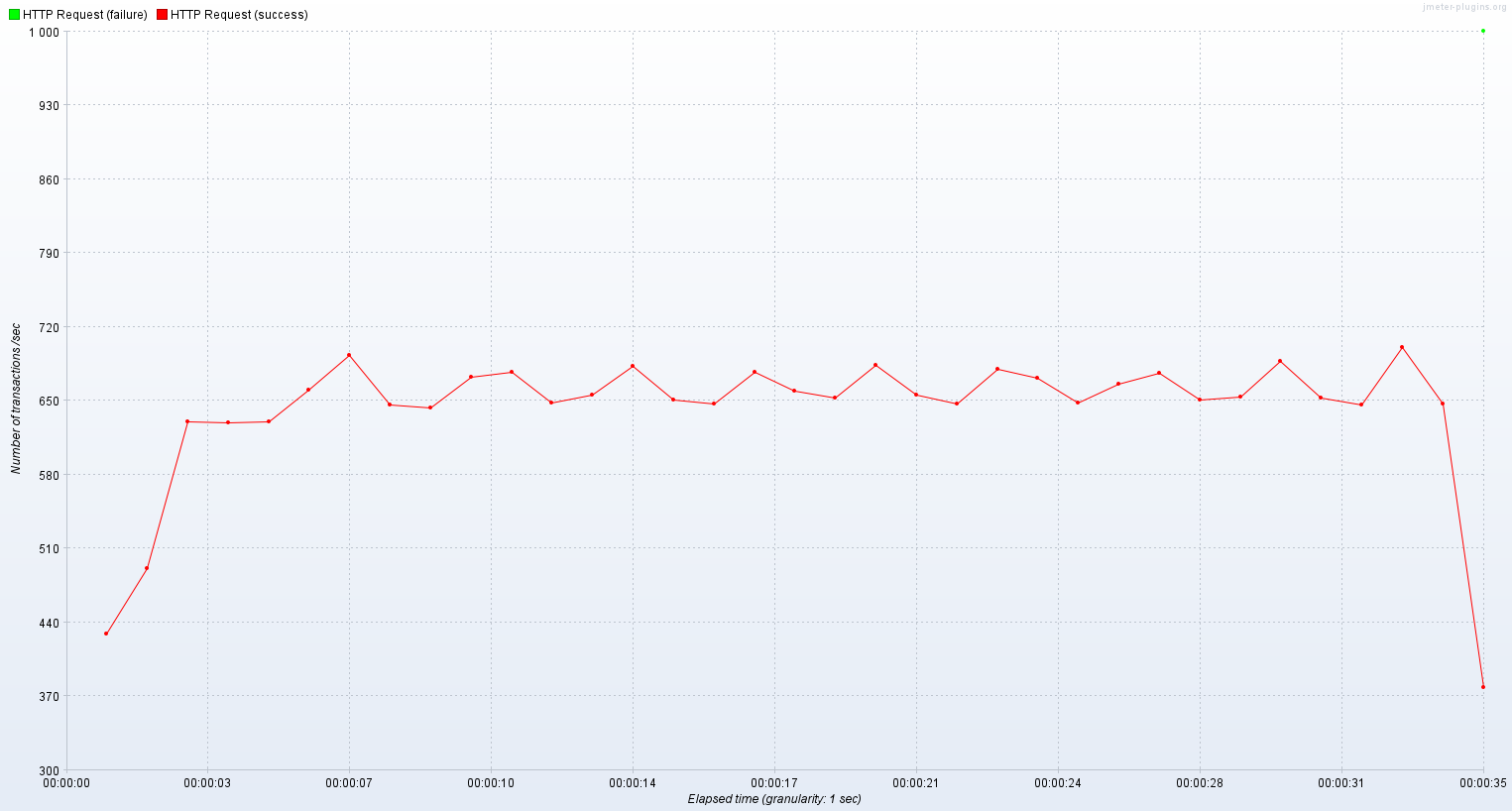
기존 스레드의 TPS는 가상 유저가 500일 때와 별다르지 않았고 응답시간은 거의 2배가 되었다.
가상 스레드
TPS
응답시간
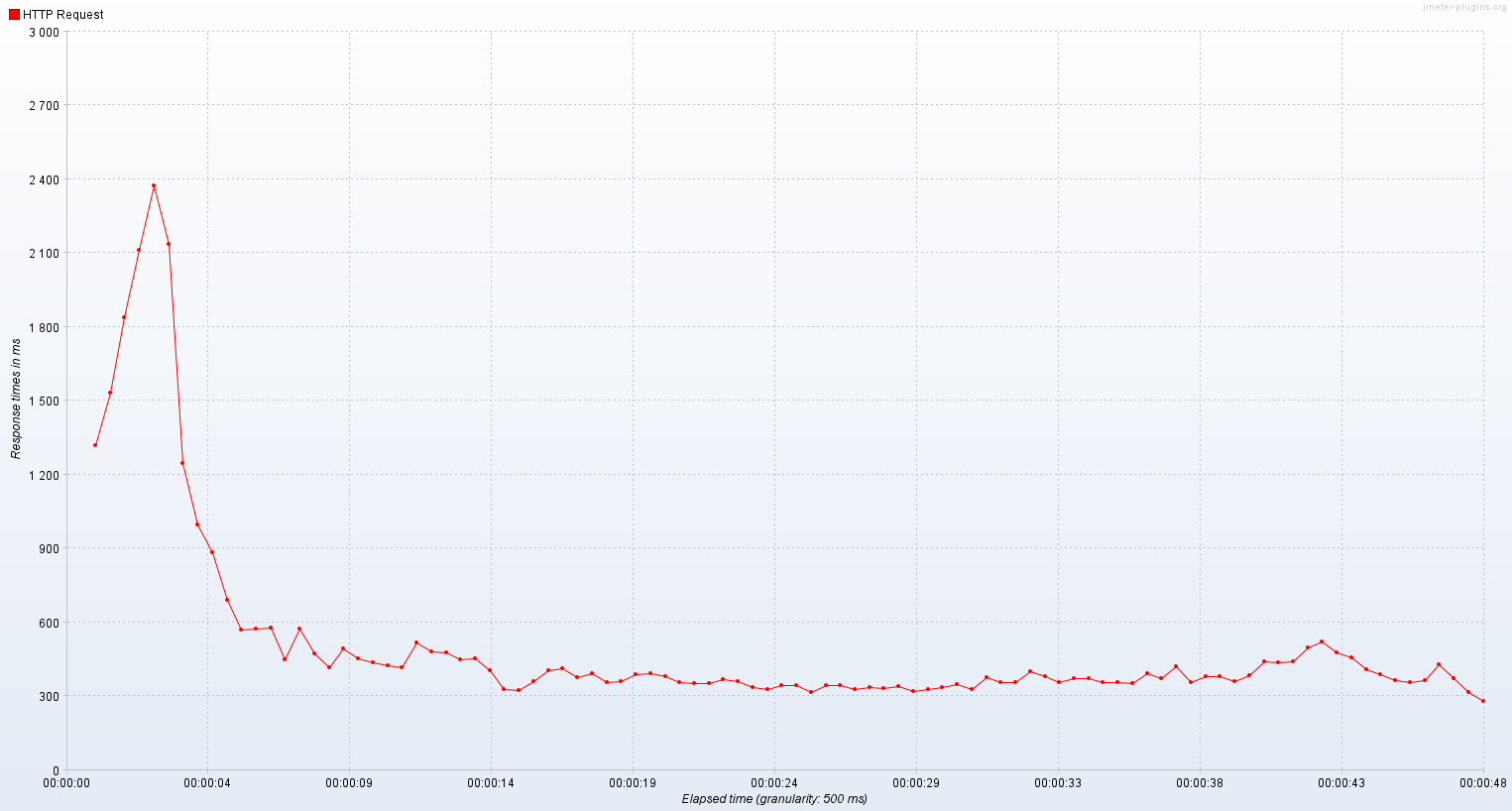
가상 스레드로는 2400 ~ 3000 TPS를 기록했고 평균 응답시간은 300 ~ 400ms였다.
확실히 기존 플랫폼 스레드만을 사용했을 때보다 유의미하게 성능이 개선되는 것을 확인할 수 있었다.
가상 스레드 주의사항
이렇게 좋아보이기만 하는 가상 스레드이지만 주의해서 사용하지 않으면 오히려 사용하지 않는 것보다도 못한 경우가 될 수 있다.
- 풀링하지 말 것
- 가상 스레드는 생성하는 비용은 적지만 하나의 작업을 실행하고 GC에 의해 제거되게 설계되었으므로 풀링해놓고 계속 사용하는 것이 더 낭비가 된다.
- 톰캣의 스레드 풀 설정을 해제하고
Executors.newVirtualThreadPerTaskExecutor()를 설정해준다. - 스레드 풀을 사용했던 코드는 세마포어를 사용하게 변경해야 한다.
- 스레드로컬(ThreadLocal) 사용에 주의할 것
- 스레드 간에 리소스를 공유했던 스레드로컬(ThreadLocal)을 사용하는 대신 글로벌 캐싱 전략을 사용하도록 변경한다.
- 예를 들면 스레드로컬에 DB 커넥션을 저장해두고 사용하는 방식이 있었다면 가상 스레드 환경에서는 성능이 저하될 수 있다.
- 기존의 스레드 로컬을 보완하기 위한 Scoped Values 역시 Project Loom이 준비 중인 핵심 기능이다.
- 스레드 간에 리소스를 공유했던 스레드로컬(ThreadLocal)을 사용하는 대신 글로벌 캐싱 전략을 사용하도록 변경한다.
- CPU 연산이 필요한 코드는 실행하지 말 것
- 가상 스레드는 non-blocking I/O 작업 처리량을 늘리기 위해 설계된 스레드로써 CPU 연산 성능은 기존 플랫폼 스레드보다 떨어진다.
- 데이터베이스 I/O, 네트워킹 같은 작업을 가상 스레드에게 맡기는 것이 효율적일 것이다.
- synchronized 또는 native method을 호출하지 말 것
- 가상 스레드가 해당 함수를 만나면 캐리어 스레드(연결된 플랫폼 스레드)에 고정(pinned)되어 block하고 마운트를 해제할 수 없게 된다.
- 플랫폼 스레드로 실행해도 마찬가지이지만 가상 스레드가 플랫폼 스레드에 pinned 되면 해당 OS 스레드도 block 상태가 된다.
- 자주 사용되지 않거나 인메모리 작업을 보호하는 synchronized 까지 제거할 필요는 없다. 하지만 자주 호출되고 오랫동안 고정시키는 코드 블럭은 ReentrantLock을 사용하는 것을 고려한다.
프로그래머스 PCCP 기출문제 3번 - 아날로그 시계 (JAVA)
문제
시침, 분침, 초침이 있는 아날로그시계가 있습니다. 시계의 시침은 12시간마다, 분침은 60분마다, 초침은 60초마다 시계를 한 바퀴 돕니다. 따라서 시침, 분침, 초침이 움직이는 속도는 일정하며 각각 다릅니다. 이 시계에는 초침이 시침/분침과 겹칠 때마다 알람이 울리는 기능이 있습니다. 당신은 특정 시간 동안 알람이 울린 횟수를 알고 싶습니다.
다음은 0시 5분 30초부터 0시 7분 0초까지 알람이 울린 횟수를 세는 예시입니다.

가장 짧은 바늘이 시침, 중간 길이인 바늘이 분침, 가장 긴 바늘이 초침입니다.
알람이 울리는 횟수를 세기 시작한 시각은 0시 5분 30초입니다.
이후 0시 6분 0초까지 초침과 시침/분침이 겹치는 일은 없습니다.

약 0시 6분 0.501초에 초침과 시침이 겹칩니다. 이때 알람이 한 번 울립니다.
이후 0시 6분 6초까지 초침과 시침/분침이 겹치는 일은 없습니다.

약 0시 6분 6.102초에 초침과 분침이 겹칩니다. 이때 알람이 한 번 울립니다.
이후 0시 7분 0초까지 초침과 시침/분침이 겹치는 일은 없습니다.
0시 5분 30초부터 0시 7분 0초까지는 알람이 두 번 울립니다. 이후 약 0시 7분 0.584초에 초침과 시침이 겹쳐서 울리는 세 번째 알람은 횟수에 포함되지 않습니다.
초기 접근 방법과 시행착오
처음에는 초기 시침, 분침, 초침의 각도를 설정하고 초를 1초씩 증가하면서 변경되는 초침의 각도와 분침의 각도, 시침의 각도를 비교해서
현재 초침의 각도 ≤ 현재 분침의 각도 ≤ 1초 뒤 분침의 각도 ≤ 1초 뒤 시침의 각도
를 만족하면 케이스를 하나 증가시키는 방법으로 접근했다.
그래서
1 | public int solution(int h1, int m1, int s1, int h2, int m2, int s2) { |
이렇게 접근했더니 11시 59분 30초부터 12시 0분 0초까지 돌아갈 때 답이 맞지 않았다.
문제 해결
도저히 풀기 어려운 와중에 수학적인 접근법을 제시해 본 사람이 있었다.
알고리즘
- 0시 0분 0초를 기준으로 H시 M분 S초까지의 총 시간을 초 단위로 구한다
- 해당 시간동안 초침이 시침과 만나는 횟수를 구한다
- 해당 시간동안 초침이 분침과 만나는 횟수를 구한다
- 위 (2)와 (3)을 더한다
- 시침, 분침, 초침이 모두 겹치는 0시 0분 0초와 12시 0분 0초가 포함되면 1을 뺀다
- (h2시 m2분 s2초까지 횟수) - (h1시 m1분 s1초까지 횟수) = 최종 정답
초침과 시침 만나는 횟수 구하기
0시 0분 0초에 모두 겹쳐있는 상태에서 출발한다고 가정해보자.
초침은 1초에 6도를 돈다.
시침은 1시간에 30도를 돌아가고 1시간은 3600초이므로 시침은 1초 동안 도 즉 도 돌아간다.
초침이 1바퀴를 돌아 제자리로 온 뒤에 다시 움직여서 시침과 만나는 시간을 식으로 세우면
여기서 좌변은 t초 후의 초침의 각이고 우변은 t초 후의 시침의 각이다.
식을 정리하면,
이므로 초 후에 초침과 시침이 만난다는 것을 알 수 있다.
초침과 시침이 만난 후에는 다시 둘이 겹쳐있는 상태이므로 또 초 후에 만나게 되므로, 초침과 시침이 만나는 주기는 초가 된다.
그러면 t초 동안 만나는 횟수는 t를 로 나누면 되는 것이다.
초침과 분침 만나는 횟수 구하기
분침은 1초에 도 씩 움직인다.
시침과 마찬가지로 식을 세우면
이므로 정리하면
이 되어서 초침과 분침은 초마다 한번 씩 만나게 되는 걸 알 수 있다.
코드로 옮기기
총 시간을 구하는 함수와 해당 시간동안 분침, 시침과 만나는 횟수를 구하는 함수를 따로 분리하였다.
1 | /** |
그리고 문제에서 시작 시간이 0시 0분 0초일 때 1회 알람이 울린다고 설명이 있으므로
알고리즘에서 세웠던 식에 추가적으로 작업이 필요했다.
최종 코드
1 | class Solution { |
느낀점
사실 수학적인 풀이는 다른 사람의 풀이를 약간 참고하였는데
알고리즘 문제 풀이를 할 때는 역시 프로그래밍적 구현도 중요하지만 수학적인 접근 방법을 먼저 생각해보는 것이 좋은 것 같다.
ElasticSearch 성능 최적화
Heap Size
일반적으로 메모리의 50%를 힙으로 할당하는 것을 권장하지만 힙 사이즈가 32G 이상으로 커질 경우 단점이 있다.
힙 사이즈가 크다고 무조건 성능이 좋아지는 것이 아니다. 오히려 32G 이상의 힙 사이즈는 성능을 저하시킨다고 한다.
이건 비단 ES 뿐만 아니라 JVM을 사용하는 모든 앱이라면 공통으로 적용되는 점이다.
이유
JVM은 OOPS(Ordinary Object Pointers) 라는 것으로 메모리의 주소를 관리한다. C의 포인터랑 비슷한 개념이다.
예전 32bit OS의 경우 메모리가 4G이므로 메모리 주소 찾는 게 그렇게 오래 걸리지 않았다.
하지만 64bit인 경우 메모리 주소를 찾는데 너무 오래 걸리므로 JVM은 Compressed OOPS라는 기법을 사용하여 메모리 주소를 관리하기로 한다.
원리는 32bit 주소에 offset bit를 3비트 추가하여 32bit * 8 개의 메모리 주소를 참조할 수 있게 하는 것으로 대략 32GB의 주소값까지 표현할 수 있게 된다.
하지만 힙 사이즈가 32G보다 커질 경우 이 Compressed OOPS 방식을 사용하지 않고 그냥 OOPS를 사용하여 메모리 주소를 찾는데 매우 오래 걸리게 된다.
Compressed OOPS 방식의 35bit 주소에서 offset 3bit를 버리기 위해 shift left 3 ( << 3 ) 연산을 하게 되는데 이때 메모리 주소의 시작점이 0이 아니라면 여기에 메모리 시작 주소를 더해야 하는 연산이 추가로 들어간다. (Non-zero based)
하지만 메모리 주소의 시작점이 0이라면 shift left 3 (<< 3)만 해도 원래 주소를 알아낼 수 있다. (Zero based)
이는 JVM으로 oops 방식을 확인하는 명령어로 확인해볼 수 있다.
- 메모리가 64G인 시스템에서 힙을 31G로 준다면?
1
java -Xmx31G -XX:+UnlockDiagnosticVMOptions -Xlog:gc+heap+coops=debug -version
1
Heap address: 0x0000001000800000, size: 31744 MB, Compressed Oops mode: Non-zero disjoint base: 0x0000001000000000, Oop shift amount: 3
이런 식으로 base 주소가 0이 아님을 확인할 수 있고 Non-zero base라고 표시된다.
- 이번엔 힙을 30G로 준다면
1
java -Xmx30G -XX:+UnlockDiagnosticVMOptions -Xlog:gc+heap+coops=debug -version
1
Heap address: 0x0000000080000000, size: 30720 MB, Compressed Oops mode: Zero based, Oop shift amount: 3
Zero based 모드라고 표시되는 것을 확인할 수 있다.
그리고 ES는 OS의 나머지 여유 메모리를 파일시스템 캐시로 이용하기 때문에 이 캐시의 크기를 더 늘리는 것이 더 좋은 성능을 낼 수 있다고 한다.
즉, OS의 메모리 절반을 힙 사이즈로 할당하면 나머지 절반은 ES가 캐시로 사용한다는 얘기.
또 다른 이유로는 힙 사이즈가 클 경우 gc가 빈번하게 일어나는 앱에서는 힙에 비례하여 cpu 사용량이 증가하고 stop the world 시간이 늘어나기 때문에 너무 큰 힙 사이즈는 좋지 않을 수 있다.
이건 JVM 애플리케이션의 공통 사항이다.
Mapping
인덱스를 생성하기 전에 인덱스 템플릿을 생성하고 매핑을 적절히 해주는 것이 좋다.
특히 string 필드는 ES에서 기본적으로 text와 keyword 타입을 둘다 생성하기 때문에 용량을 낭비하고 검색 성능이 저하된다.
따라서 텍스트 분석이 필요하고 검색 기능이 필요한 필드는 text만 매핑하고 나머지 필터링을 위한 필드는 keyword로 매핑하여 불필요한 연산이나 용량을 제거해주는 것이 좋다.
하지만 반대로 Mapping에 대해 자세히 이해하지 못하고 획일화된 Mapping만 사용한다면 NoSQL의 장점을 활용하지 못하게 된다.
인덱스의 Mapping을 변경하는 작업은 그렇게 어려운 일이 아니므로 조금씩 공부하면서 변경하는 것도 좋다.
Shard
샤드는 기본적으로 인덱스 1개와 매핑되어 있고 샤드의 갯수는 인덱스 1개당 1개 이상이다. (1대다 관계)
노드가 여러 개인 경우 샤드를 분산배치함으로써 클러스터링, 로드 밸런싱 등이 가능해진다.
샤드의 갯수
ES에서는 노드 1개당 샤드의 갯수가 너무 많으면 좋지 않다고 한다.
샤드의 갯수가 너무 많으면 마스터 노드가 샤드를 추적할 때 연산량이 많아져 성능이 저하된다.
일반적으로 Heap 사이즈 1GB 당 20개 미만 (예. Heap 8GB -> 샤드 160개) 으로 하는 것이 좋지만 이보다 더 적게 할 것을 권장한다고 한다.
샤드의 용량
샤드 1개의 용량은 약 20GB~40GB 정도로 유지하는 것이 좋다고 한다.
샤드에는 Lucene 엔진 인스턴스로서 정보를 보관하고 있는 세그먼트가 있다.
세그먼트는 데이터가 많을수록 커지기는 하는데 중요한 점은 데이터가 적을 때의 세그먼트와 데이터가 많을 때 세그먼트 크기는 별로 차이나지 않는 것이다.
이 말은, 샤드에 적재된 데이터가 적을 때 1GB 당 오버헤드가 데이터가 많을 때 1GB 당 오버헤드보다 월등히 크다는 것을 말한다.
이 때문에 50MB 용량의 샤드 1000개에서 쿼리하는 것보다 50GB의 샤드 1개에서 쿼리하는 것이 대부분의 경우 훨씬 더 빠르다.
50MB의 샤드와 50GB 샤드의 세그먼트 크기는 별 차이가 없는데, 전자는 1000개의 세그먼트를 합치는 과정에서 엄청난 리소스를 필요로 하기 때문이다.
그래서 이미 샤드의 갯수가 많아졌을 경우 강제 병합 과정을 통해서 세그먼트를 병합해 오버헤드를 줄여 성능을 개선할 수 있다.
하지만 또한, 50GB 이상으로 너무 크게 하지 않을 것을 권장하고 있다.
ElasticSearch >= 8.3 는 다르다!
해당 프로젝트를 진행한 날짜가 2022년이고 당시에 ES 7.10 버전을 기준으로 작성했었는데, 최근 ES 문서를 확인해보니까 8.3 버전 이상부터는 **샤드의 갯수 규칙 (힙 1GB 당 20개 미만)**이 다르다고 한다!
새로운 팁
8.3 버전 이상에서 ES의 경험 법칙에 따르면 각 데이터 노드의 인덱스 당 매핑된 필드 수 X 1kB + 0.5GB 를 권장한다고 한다.
예를 들어서, 데이터 노드가 1000개의 인덱스 샤드를 보유하고 있고, 각 인덱스가 4000개의 필드가 매핑되어 있다면
1000 x 4000 x 1kB = 4GB에 추가로 0.5GB를 할당해 4.5GB 이상의 힙 크기를 할당해줄 것을 권장하고 있다.
또, 샤드 당 데이터의 크기는 10GB~50GB를 권장하고 있다.